Embedding模型简介
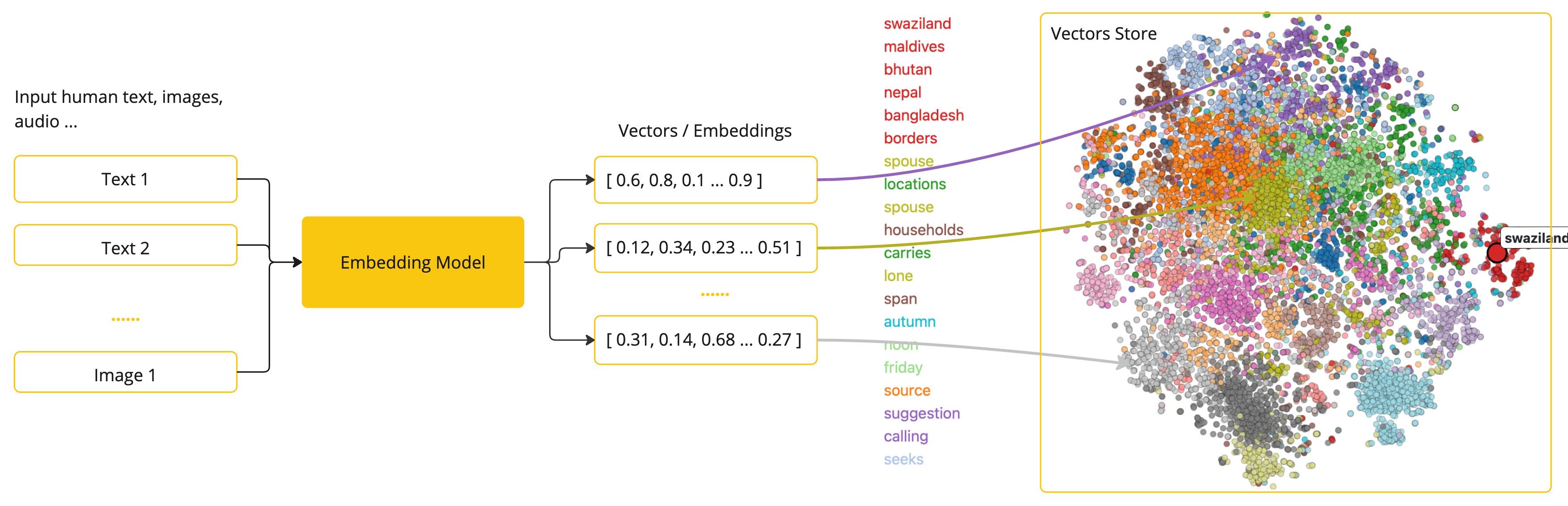
Embedding模型是将文本数据(如词汇、短语或句子)转换为数值向量的工具,这些向量捕捉了文本的语义信息,可用于各种自然语言处理(NLP)任务。工作原理
Embedding模型将文本映射到高维空间中的点,使语义相似的文本在这个空间中距离较近。例如,“猫”和”狗”的向量可能会比”猫”和”汽车”的向量更接近。优点
- 捕捉复杂的词汇关系(如语义相似性、同义词、多义词)
- 超越传统词袋模型的简单计数方式
- 动态嵌入模型(如BERT)可根据上下文生成不同的词向量
LangChain支持的向量数据库
LangChain支持多种向量数据库,每种数据库具有不同的特性。以下是部分支持的向量数据库及其功能:文本向量化
使用OpenAI的Embedding模型进行文本向量化的示例代码:Qdrant向量库存储
Qdrant是一个高性能的向量数据库,用于存储嵌入并进行快速的向量搜索。安装Qdrant
使用Docker安装Qdrant:- 端口6333:用于HTTP API
- 端口6334:用于gRPC API
集成LangChain4j与Qdrant
- 添加Maven依赖:
- 创建Qdrant客户端:
- 创建索引:
- 配置Qdrant Embedding Store:
- 文本生成与存储:
向量查询与过滤
- 基本向量查询:
- 带元数据过滤的查询:
- 常用过滤器:
- 输出结果:
结论
本文档详细介绍了Embedding模型的概念、LangChain支持的向量数据库、文本向量化过程,以及如何使用Qdrant向量库进行存储和查询。通过这些步骤,你可以快速搭建基于Qdrant的高效向量搜索系统,为自然语言处理任务提供强大的支持。PIG AI应用开发平台 | 适合中大型企业构建自主可控的AI中台
为Java开发者提供全栈式AI工程化解决方案,强类型/高可维护性架构,内置30+主流大模型支持。
- 🔍 知识引擎体系:RAG 知识引擎全自动化多模态解决方案
- 📝 AI-OCR 中枢:复杂非标场景高精度识别
- ⚙️ 业务智能融合:函数编排 + Chat2SQL,无缝对接现有业务系统
- 🛡️ N维风控体系:敏感词/IP/Token/User 规则控制引擎
文档有误?请协助编辑
发现文档问题?点击此处直接在 GitHub 上编辑并提交 PR,帮助我们改进文档!
文档有误?请协助编辑
发现文档问题?点击此处直接在 GitHub 上编辑并提交 PR,帮助我们改进文档!